Data Management
For more than 40 years, the national park has been producing manifold data on its protected resources serving for scientific analysis and management tasks. This creates an increasing responsibility as data does not lose its value after project closure, but gains more benefit over time by giving evidence of long-term evolution in the national park.
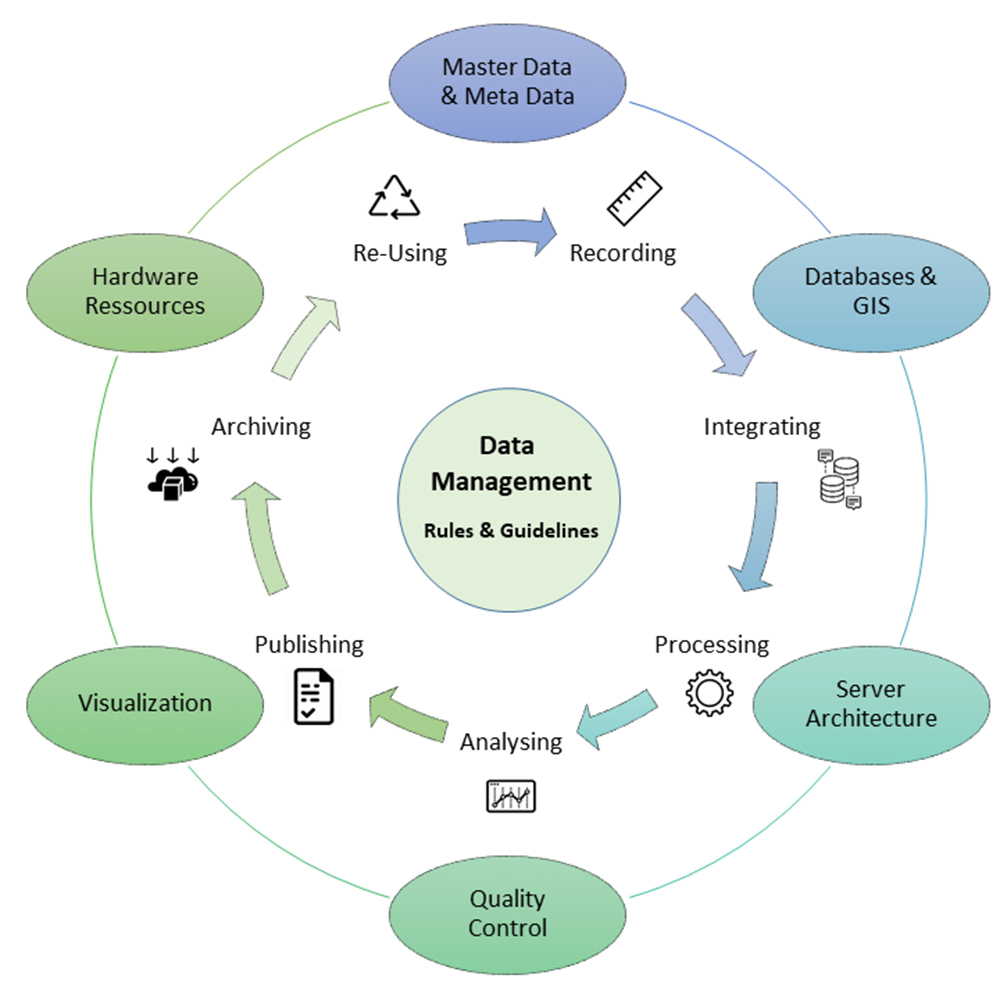
Data management is like a hub collecting, analyzes, processing and distributing data. Specific tools, rules and guidelines are crudial elements..
Data management is a permanent responsibility that ensures current data operations as well as the long-term availability of data stocks that are presently not in use. For this reason, the topicality of the data is as important as its archiving.
National park history implies a large thematic variety of data ranging from animals, plants and species communities, to soil and geology, habitats and landscapes, climate and hydrology, and further on to disturbance events and dynamic processes and all their changes in space and time.

Habitats and landscapes are the home of species. Land cover data often result from remote sensing e.g. from aerial photography or satellite imagery and cover large areas, smkaller areas rather need terrestrial vurveys..
Data management creates the framework for turning data into knowledge. This means more than just storing a file, especially if there are numerous data resulting from various sources and accumulating by increasing time periods that should all be usable for future yet unknown purposes and contexts. Data management integrates data and descriptive metadata as well as reports and publications in a way that both expert and non-expert users can make use of the data.
As all data always has a direct or indirect spatial reference, it is referred to as geodata and managed within a spatial data infrastructure (SDI). The national park SDI connects to a relational database management system (RDBMS). This RDBMS allows for the secure long-term management of data stocks permanently increasing by number and size and provides simultaneous multi-user access.
National park data management also develops user specific applications that integrate data resources into current digital work processes such as apps for mobile field data collection, automated data pipelines from field sensors or web based data entry forms.

Data on animals, plants and their communities arise from defined field mappings or a random observations. Some recordings happen regularly and need standardized methods and data structures to generate comparable time series.
In addition to continuous operational services, the data management team also runs temporary projects. Currently, we are working on the harmonization of research-relevant basic datasets for the two Bavarian National Parks in order to enable future cross-regional research approaches (until the end of 2023). Another project concentrates on the successive development of a comprising research database archive that will provide documentation of both completed and ongoing projects. One of the missions recently accomplished is the transformation of our operative geodata into the new standard coordinate reference system ETRS89/UTM (2019-2021).
Contact:
Annette Lotz
Head of data management team, spatial data infrastructure (SDI), cross-disciplinary integration of applications-data-interfaces, climate observation network.